6 uncommon principles for effective data science
Motivation
The more I delve in data science, the more convinced I am that companies and data science practitioners must have a clear view on how to cut through the machine learning and AI hype, to implement an effective data science strategy that drives business value. This article hopes to establish a framework to conceptualize and implement effective data science projects.
Why should you care
Showing that you as a data scientist can derive meaningful insights which improve revenue and profits will result in yourself being more valuable to the company. With highly optimized and easily implementable machine learning and deep learning libraries, any data monkey can build sophisticated AI algorithms with just a few lines of code. However, a sophisticated model does not equate to an effective model. Knowing how the model output translates into real world application is key.
From a company’s perspective, data scientists, as with any other employee, get paid according to the value they generate. If a company pays employees more than the value they bring, then the company loses money. Clearly not a sustainable long run strategy. Yes, data scientists are drawing high salaries now, but if companies cannot extract the value they think they can from data science, salaries and demand for data scientists will eventually fall.
Problem: Data scientists tend to focus more on the means than the ends
Because of the results AI researchers have achieved over the last few years (play GTA, compose Chopin-esq music pieces), many companies are jumping on the bandwagon to herald the new era of AI.
This is all well and good, but because of the nascent application of data science in a business context, information asymmetry exists. Data scientist practitioners tend to have a technical background, and often view their main goal as building state of the art algorithms. On the other hand, other employees view AI as a black box, commonly through the lens of the high profile breakthroughs from AI researchers (for example, AI capable of beating top Go players). Because of the disjoint between the technical and the commercial segments of the business, output from data scientists may not be actionable or commercially meaningful.
Solution: Don’t miss the forest for the trees; Practical data science is about driving value, not about optimizing accuracy
We can think of practical data science as a stool with 3 legs: programming, statistics, and business understanding, and if we are missing any one leg, the stool collapses. We all know this, but business understanding is rarely if ever the focus in data science articles or forums.
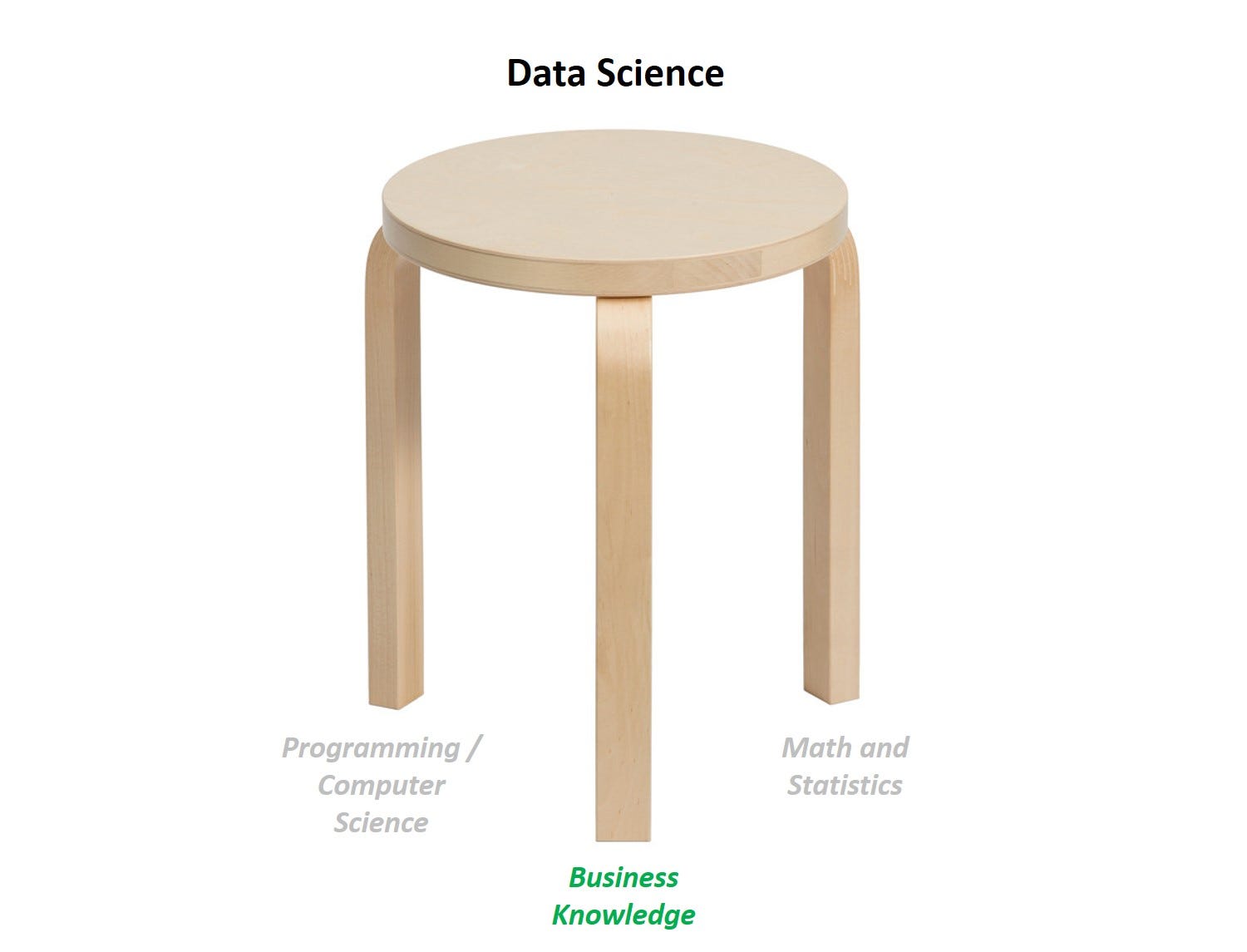
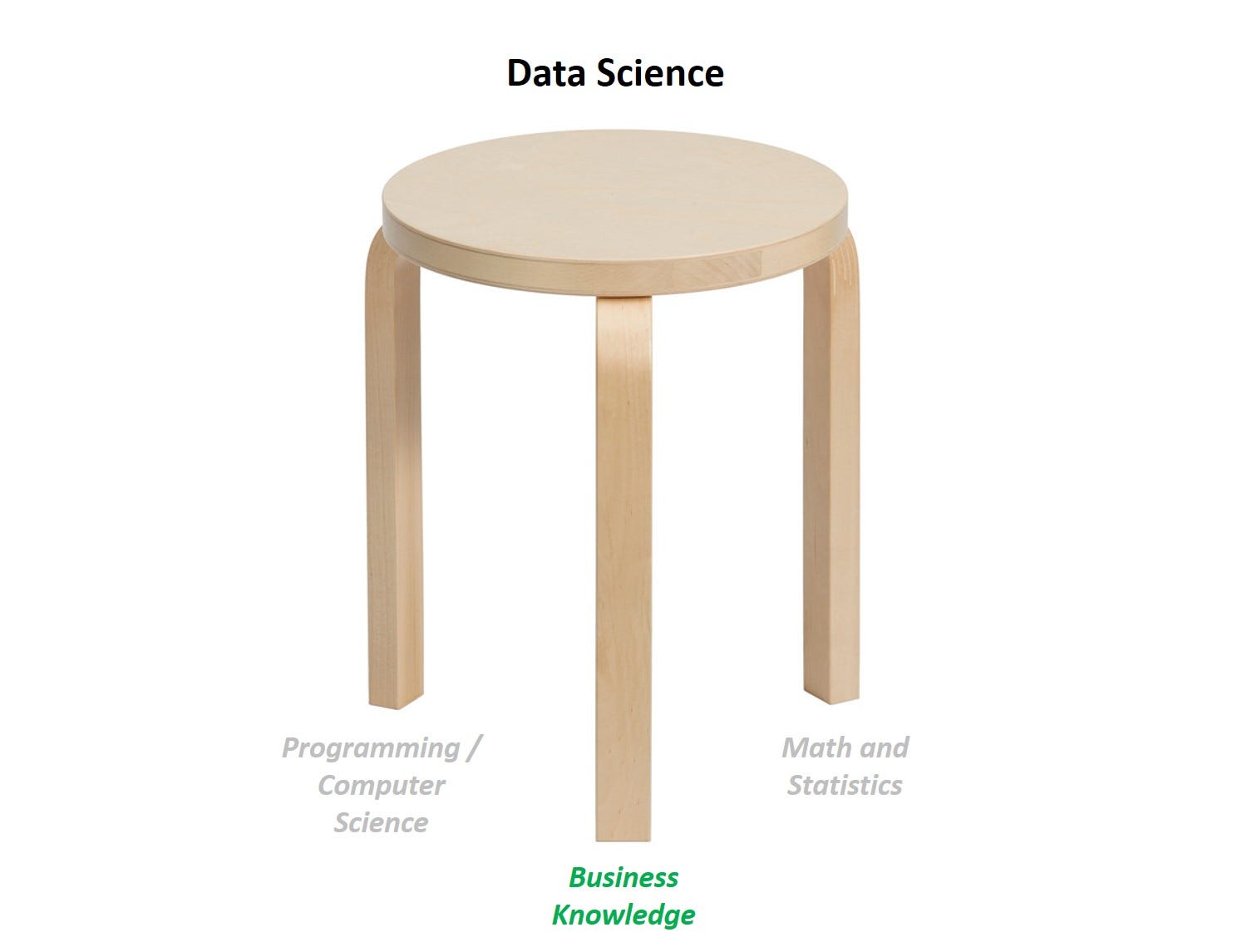 The three pillars of data science
The three pillars of data scienceProgramming and math are necessary but not sufficient to be an effective data scientist, as technical skills are merely a means to an end. Helping companies improve customer retention, helping the poor get loans, improving health by diagnosing diseases earlier — these are the goals that data scientists should focus on; machine learning / AI is merely a means to achieve that end.
The 6 principles for effective data science
Sticking to the six principles below will enable data scientists conceptualize and implement effective projects.
1. Understand the AI hierarchy of needs
Much like how humans need food, water, and air before they can achieve self-actualization, building a reliable data flow is key to doing anything with data. Only when data is accessible then can it be explored and transformed. When cleaned data can be easily explored, better customer understanding can be achieved. Monica Rogati’s excellent article, ‘The AI Hierarchy of Needs’, provides a clear framework to think about this.
Many companies want the outcome AI brings, but do not have the right infrastructure in place to implement machine learning. Companies should be aware that machine learning / deep learning comes late in entire data stack. Data first has to be reliably collected, then can it be transformed and subsequently explored. A broken upstream process (for example, if tracking is inaccurate) will affect the cleanliness of data and ultimately the insights gained it. Only when data is clean and easily explored, then can it be used for BI, analytics, and AI.
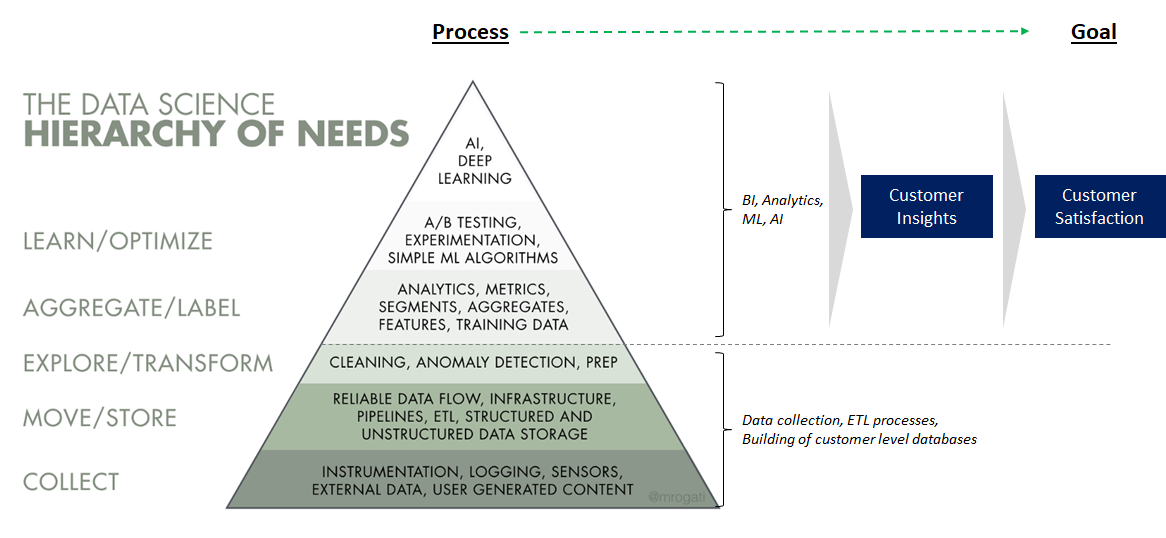 Diagram adapted from Monica Rogati’s excellent article, ‘The AI Hierarchy of Needs’
Diagram adapted from Monica Rogati’s excellent article, ‘The AI Hierarchy of Needs’ Implications of the AI hierarchy of needs — scale up data infrastructure before thinking about machine learning or deep learning
This hierarchy implies that companies should hire according to this order of needs. What does this mean? If your company is not set up to scale machine learning yet, then the focus should be on those tasks instead of deep learning. As with coding, it is a sequential process where the right building blocks must first be in place before the next level can be achieved.
A recipe for disaster is for a data scientist experienced in modelling to be hired at a start-up that does not have the proper tracking and databases in place. Employees should also have their expectations in check pertaining to the work they will be doing prior to joining a company.
As a data scientist, knowing how to properly design table schemas or build data pipelines can be important but yet underrated skills which many companies require, especially since most data science courses and machine learning competitions tend to focus on the ‘sexier’ aspects of machine learning.
2. Build models that answer the right questions
Early decisions, and consequently early assumptions in projects, often have a disproportionate impact on the entire project. The decision you make a day or week into the project — assumptions about the needs of end users, how the output of the model can be used — have the most significant impact on the effectiveness of the model. As decisions are made later and later in the project, their influence decrease. Choosing how to clean dirty data or what features to use will affect the accuracy of the model, but the biggest factors that determine if a machine learning model can be deployed into production come from the questions you ask at the start of the project.
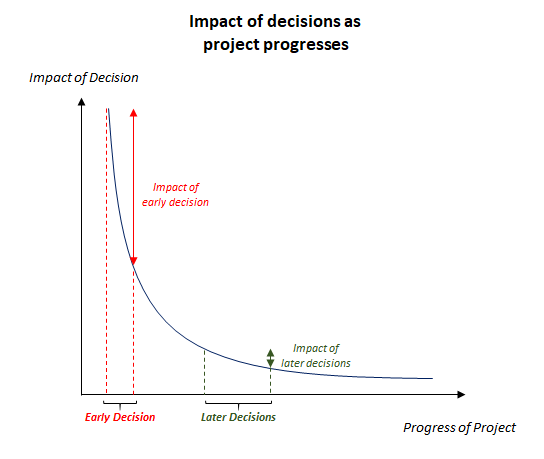 Early decisions have disproportionately large impact on projects
Early decisions have disproportionately large impact on projectsIt is easy to understand this point on the surface, and yet few people consider the implications.
In order to build a model that has an actionable outcome, the following has to be done before a single line of code is typed: communicating with ends users, understanding business rules that are already in place, looking at existing data and thinking of how to define the “ground truth” for the model to be trained on such that it is meaningful for end users, understanding the limitations of the proposed model, and stress testing the predicted output of the model with business users.
Here’s an example to illustrate this point.
Building a churn prediction model
You are approached by the marketing department to build a machine learning model to predict which customers have churned. The marketing department tells you that having such an output is useful so they can better re-target customers to improve customer retention. As a data scientist, this seems like a simple, straightforward task. Build a binary classification model with output of 1 being a churned customer and 0 being an active customer. In fact, you tell your colleagues that you can one-up their request by giving them the probability that a customer churns.
Further discussions take place, and you learn that marketing defines churned customers as customers who have not ordered in a year or more. You decide to follow their existing logic and label your model’s targets as such.
Your present your plan, and the marketing department gives you the go ahead to build the model. You spend weeks pulling and cleaning data, defining your loss function, determining your cross-validation strategy, training and tuning your model, validating your results, and end up with an AUC of 0.9. You are elated with the results and proudly present your findings to the marketing team, telling them what data and model was used, and how to interpret AUC.
The marketing department has comments:
Subscribers who recently signed up but not made orders are labelled by the model as churned users. This should not be the case as the order cycle is longer. More broadly, users who sign up at different times should have different definitions of churn. A frequent customer who does not buy in six months may be considered as churned, while a new user who has not bought in six months may not be churned, because the normal buying cycle is a year or more.
The marketing department realizes that customers predicted by the model to churn are already targeted from existing retention efforts. They implemented a simple business rule, where customers who have not purchased in six months are already given the max discount possible. Can the model output provide reasons for customer churn?
Takeaways from the churn prediction model
No matter how accurate the model is, answering the wrong question is time wasted.
The business may not always know what it needs in advance, as business managers may not understand how machine learning works. Challenge what the business tells you. In this case, is predicting churn useful? Or do we want to instead predict how likely will a customer respond to an existing churn offer so that marketing can better target their existing campaigns? Being able to do this efficiently involves understanding the business and customers.
Definition of targets is extremely important. How the business defines churn, and how you want to train your model may be different, as training the model with existing churn definitions can result in predictions that do not make business sense. In this case, being aware of different segments of customers (for example, a top customer and a new user) and their different lifecycles is key to getting a meaningful prediction. Understanding the model output based on the way the model is trained is necessary.
3. Pick projects that add the most value for the business
Asking the right questions is also important when choosing what projects to work on. Ideally, prioritized projects should be the ones that have the biggest areas of opportunity for the business. Machine learning projects take time to roll-out, and the cost of undertaking the wrong projects may exceed the benefits.
The importance of asking the right questions is further highlighted given the empirical nature of machine learning where results are not guaranteed. Conducting exploratory data analysis may not yield much insight, and building a model may not yield results better than the existing business rules implemented. There needs to be a significant asymmetry between the gains (they need to be large) and the costs (small or harmless) of undertaking a project, and it is from such asymmetry that empirical projects (trial and error)can produce results. Convexity is a mathematical property that represents this.
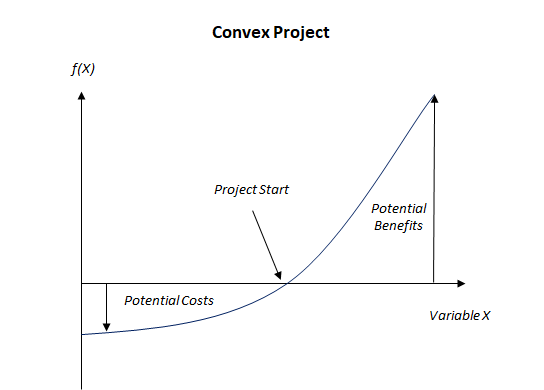 Graphical representation of a convex strategy
Graphical representation of a convex strategyMachine learning projects can be likened to cooking, which largely relies on trial and error, as we have not been able to concoct a dish directly from chemical equations. We take rice, and add different combinations of ingredients, say soy sauce and turmeric powder, taste to see if there’s an improvement from the interaction between ingredients. We then keep the good recipes and discard the rest. Importantly, we have the option and not the obligation to keep the result, which allows us to keep our upside while severely limiting the downside. In the case of machine learning, if models are not yet implemented in production, the downside is time spent working on those models. This “optionality” results in the convexity of machine learning projects as it allows a data scientist to get more upside than downside by selecting the best model and forgetting the rest. Critically, this means that the projects selected has to have a high potential upside for the business.
Calculating the size of the opportunity before building a machine learning model can help determine a project’s potential impact on the business. This potential impact can then be weighed against the estimated time spent on the project to gauge project convexity.
Generic formula to calculate size of business opportunity:
number of customers affected * target size of effect = Estimated project impact
Embark on projects which directly impacts business levers. It’s also important to ensure that the output of machine learning models directly impact business levers. This would result in projects which are directly actionable. As an example, an e-commerce company may ask its data science team to identify customers which have a strong intent towards a certain brand or item category. Merely predicting whether a customer has a strong intent or not is not enough, as intent does not directly impact any business levers. Ideally, we still want to send those with strong intent what they are interested in. Identifying customers with intent is only half the equation — identifying what products to serve these customers is just as important.
4. Iterate Fast
Iterating fast is almost always best with convex strategies. In order to take advantage of the empirical nature of machine learning and the optionality we have to keep the best models, we should reduce the cost per attempt. A large exposure to a single trial has lower expected returns than a portfolio of small trials when we’re dealing with a convex function where our cost is the time spent per iteration. Reducing the cost per attempt will mean having a higher number of trials, and allocating 1/N of our time across N trials allows us to minimize the probability of missing rather than maximizing profits should we have a win.
In practice, what this means is that baseline models need not be trained on the full data before implementation (e.g. models can be trained solely for a single geography), or that first building simple machine learning models can help gauge whether an output from a model can be implemented in practice.
Simple technologies can have a big impact when correctly applied
Less is often more. It took about a million years between discovering fire and using fire to generate power via a steam engine. It is sometimes the simplest technologies that are ignored. In practice there is no premium for complexification; in the corporate world there is. Looking at the latest technologies used in AI research invites complexity, where in practice implementing simple business rules after data exploration may be all it takes to extract value from data.
Having a variety of perspectives is important; as the saying goes: if all you have is a hammer, everything looks like a nail. One might not see things clearly if one relies too much on a particular tool, method, or mindset. In practice, the results achieved by combining data exploration with business acumen (for example, tailored customer segments) is quick to roll out and surprisingly difficult for machine learning models to beat. Using data in such a way enables a data scientist to iterate fast, as well as helps build a good baseline to measure machine learning models against.
5. Data is no magic bullet (not yet at least)
Understanding the limitations of data and how machine learning algorithms work is important to know which models are worth building. The effectiveness of machine learning algorithms is only as good the data used, and many times, the data collected does not fully represent reality, especially when it comes to human behavior.
This is why AI has had greater breakthroughs in some fields and not others. In computer vision problems, the numbers used to represent an image or video exactly represents what the model is trying to predict. To phrase it in another way, the entire hypothesis space is encoded in the data in computer vision problems. In contrast, share prices are heavily influenced by human biases, and using a neural network to predict stock prices using daily closing prices, volume traded, and news sentiment analysis will not yield as good a result as in computer vision problems, precisely because the human psychology and emotions behind why shares and bought and sold cannot be encoded in data.
Implications: Scale down problem, and get input from the business to better encode information in the model
Scale down scope of problem. This does not mean that data science cannot be applied when human behavior is involved, but its use has to be scaled down. For example, hedge funds use NLP to conduct sentiment analysis, which is just one of the tools used to augment investing decisions. Or in the case above, instead of predicting when will a customer churn, predicting how likely a customer will respond to a churn email offer based on the customer’s previous email open and click through rates may be more meaningful.
Use business knowledge to improve raw data. By incorporating business knowledge, new variables can be created from raw data to enable machine learning models to better discover useful patterns. This improves model performance with the same data. Data scientists are experts in their own domain, and the exploratory data analysis done by data scientists will often not yield as much as the insights which come from business experts. As an example, an e-commerce business have products are tagged to thousands of subcategories, many of which are extremely similar. With business knowledge, more appropriate tagging of products can be done to better represent distinct subcategories. This allows the model to better understand the differences in subcategories and produce better results.
As Tirthajyoti Sarkar so eloquently puts it in this article:
“For practical machine learning, it might sometimes be easier for a human designer to specify a representation that captures knowledge about the relative probabilities of hypotheses than it is to fully specify the probability of each hypothesis.
This is where the matter of knowledge representation and domain expertisebecome critically important. It short-circuits the (often) infinitely large hypothesis space and leads us towards a highly probable set of hypothesis which we can optimally encode and work towards finding the set of MAP hypotheses among them.”
6. Models must be carefully evaluated by the business before deployment
Last mile problems are the final hurdles to deploying a machine learning model. Asking a machine learning model to provide the right answers 100% of the time is impossible and having recommendations from models that violate basic business rules is not uncommon.
Using the churn prediction model again as an example, predicting that a user churns a few weeks after they sign up is not meaningful. Business stakeholders should thus carefully evaluate the output from machine learning models before deployment.
Apply business rules as a safe-guard
Having an extra layer of business rules is imperative for quality assurance, as well as help prevent a faulty machine learning model that compromises customer experience from being launched. Deciding what business rules to implement stem from sanity checks conducted by the business.
Concretely, the sanity checks can include:
ensuring model output is meaningful by validating the model output against different customer characteristics. The exact customer characteristics used for validation highly depends on the model’s use case. If the model is predicting when top customers will churn, check if the model output only includes top customers, and including characteristics like last site browse date, last order date, average basket size, number of orders made can help to validate the output
Conclusion
The six principles behind effective data science are not complex. You can liken them to hyperparameter tuning, where these hyperparmeters determine, on a scale from 0 to 100, how valuable the model output is to the business. Tweaking any one of these will affect the value the project brings.
Ensuring that there is a AI hierarchy of needs where data is first collected and subsequently cleaned and transformed in a database is crucial for scalable machine learning.
Asking the right questions before embarking on any project and ensuring the model output answers those questions asked will help ensure the output of the project is meaningful.
Thinking about convexity and weighing the potential costs and benefits of a project will help with picking the ones that effect the most value for the business.
At the same time, having a mindset to iterate fast allows us to have more attempts, which minimizes the probability of us having trivial results — especially important in machine learning where it’s exploratory in nature. An extension of iterating fast is to aim to use analytics or machine learning techniques that are the most effective and not necessarily the most complex.
Being able to understand the limitations of data will help define the scope of a project, to ensure the output is not gibberish. Gaining insights from the business to better engineer features can help improve models.
Lastly, sanity checks by the business are necessary safeguards to prevent recommendations leading to a poor customer experience.








No comments: